こちらは強化学習苦手の会です。強化学習若手の会の分会になります。
本会の目的は、強化学習への理解を深めたい人同士の交流です。若手の会と異なるところは、実際に自分で手を動かしていくことの支援に重点を置いている点です。一人で強化学習を勉強していくのがつらい方、初学者の方を歓迎しております。
本会では、個人が自由に設定した強化学習プロジェクトを進める「もくもく会」を行っています。
もくもく会では、定期的に有志で決まった時間に集まり、各々の強化学習プロジェクト(本を勉強したり、論文を読んだり、実装したりなど)を進めています。他の人も自分のプロジェクトを進めているという意識を持つことで、一人ではなかなか得られなかった進捗を生み出します。
強化学習苦手の会の活動場所はDiscordです。ご興味ある方はこちらからご参加ください。(2020.11.29 リンクが期限切れになっていたようで、更新しました。)
https://discord.gg/t5PumCmDQX
このAdvent Calendarでは、強化学習苦手の会の人々にご自身のプロジェクトでやっていることや、学んだこと、最近考えていることなど自由にご寄稿いただけると幸いです。強化学習苦手の会を盛り上げていきましょう!
| SUN | MON | TUE | WED | THU | FRI | SAT |
|---|---|---|---|---|---|---|
1 Seitaro Shinagawa | 2 | 3 Seitaro Shinagawa | 4 | 5 Seitaro Shinagawa | ||
6 | 7 あるふ(高度AI人材らしい) | 8 threecourse | 9 Katsuki Ohto | 10 Seitaro Shinagawa | 11 caesar_wanya | 12 きょうへい |
13 syuntoku14 | 14 Seitaro Shinagawa | 15 Kentaro Nakanishi | 16 Seitaro Shinagawa | 17 kiyo | 18 caesar_wanya | 19 ashigirl96 |
20 Yuji Kanagawa | 21 Kei Ohta | 22 Takuma Wakamori | 23 GO | 24 Seitaro Shinagawa | 25 Seitaro Shinagawa |
- 12/1もくもく会はイイゾ(強化学習苦手の会をはじめてみて2ヶ月、得られた効果)強化学習苦手の会(もくもく会)をはじめて2ヶ月近く経った結果 - Seitaro Shinagawaの雑記帳
- 12/3言語生成の強化学習をやっていく(手法紹介 REINFORCE編)言語生成の強化学習をやっていく(手法紹介 REINFORCE編) - Seitaro Shinagawaの雑記帳
- 12/5言語生成の強化学習をやっていく(手法紹介 Actor-Critic編)言語生成の強化学習をやっていく(手法紹介 Actor-Critic編①) - Seitaro Shinagawaの雑記帳
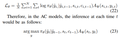
- 12/7kaggleの強化学習コンペがグダグダだった話Kaggleの強化学習コンペがグダグダだった話 - Qiita

- 12/8kaggleの強化学習コンペを少しだけ頑張った話Kaggle Haliteを強化学習で解こうとした話 - threecourse’s blog
- 12/9オフポリシー強化学習のすゝめオフポリシー強化学習のすゝめ - Qiita

- 12/10言語生成の強化学習をやっていく(手法紹介 Deep Q-learning編)言語生成の強化学習をやっていく(手法紹介 Actor-Critic編②) - Seitaro Shinagawaの雑記帳
- 12/11Q学習からDQNまでQ学習からDQNまで - あしたからがんばる ―椀屋本舗
- 12/12サッカーを強化学習する
- 12/13研究用のRLフレームワークを作ってる話研究用のRLフレームワークを作ってる話: DebugRLの紹介 - しゅんとくの雑記
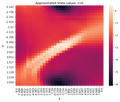
- 12/14言語生成の強化学習をやっていく 実験編 準備&コードの紹介言語生成の強化学習をやっていく 実験編 強化学習なしとSelf-Criticの比較 - Seitaro Shinagawaの雑記帳
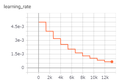
- 12/15論文紹介: Human-centric Dialog Training via Offline Reinforcement Learning[2020] Human-centric Dialog Training via Offline Reinforcement Learning · Issue #116 · cfiken/paper-reading · GitHub
- 12/16言語生成の強化学習をやっていく 実験編 REINFORCE言語生成の強化学習をやっていく 実験編 REINFORCE編 - Seitaro Shinagawaの雑記帳
- 12/17Stable Baselinesを使ってスーパーマリオブラザーズ1-1をクリアするまでStable Baselinesを使ってスーパーマリオブラザーズ1-1をクリアするまで - Qiita

- 12/18on policy と off policy の違い
- 12/19[EMアルゴリズム使った強化学習] MPOとV-MPOについて[EMアルゴリズム使った強化学習] MPOとV-MPOについて - Qiita

- 12/20より良い問題設計へ向けて: 何が強化学習を難しくするのかを理解しようより良い問題設計へ向けて: 何が強化学習を難しくするのかを理解しよう | RLog
- 12/21TensorFlow2.x ベース強化学習ライブラリの紹介tf2rl - Kei Ota
- 12/22Task-Relevant Adversarial Imitation Learning を読んだTask-Relevant Adversarial Imitation Learning を読んだ - 一日坊主
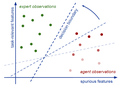
- 12/23強化学習、はじめました強化学習、はじめました | Concast

- 12/24言語生成の強化学習をやっていく 実験編 Actor-Critic with Deep Q-learningOpenAIのPPO言語生成論文を読む① - Seitaro Shinagawaの雑記帳
- 12/25OpenAIの言語生成強化学習論文を読むOpenAIのPPO言語生成論文を読む② - Seitaro Shinagawaの雑記帳







